How the AI responds
How Hamster Studio's AI agent reads your messages, runs tools, and replies — with long answers automatically moving into their own thread so the main chat stays clean.
Overview
Every message you send in a conversation is handled by an AI agent that understands your workspace — Briefs, Initiatives, Tasks, documents, skills, Methods, and connected tools. The agent reads your message, decides what to do, and either writes a response, takes an action (creating a Brief, generating a Plan, searching context), or asks follow-up questions. Responses stream word-by-word so you see the answer forming, not just a Result that appears all at once.
When the agent's reply gets long, or when it's drafting something substantial like a Brief or a Plan, the conversation moves into a child thread automatically. The parent chat stays focused; the detail lives in its own space with a clickable card pointing to it.
Hamster's chat is the entry point to the product. Most of the Refine work — turning a customer signal into a Brief — happens here.
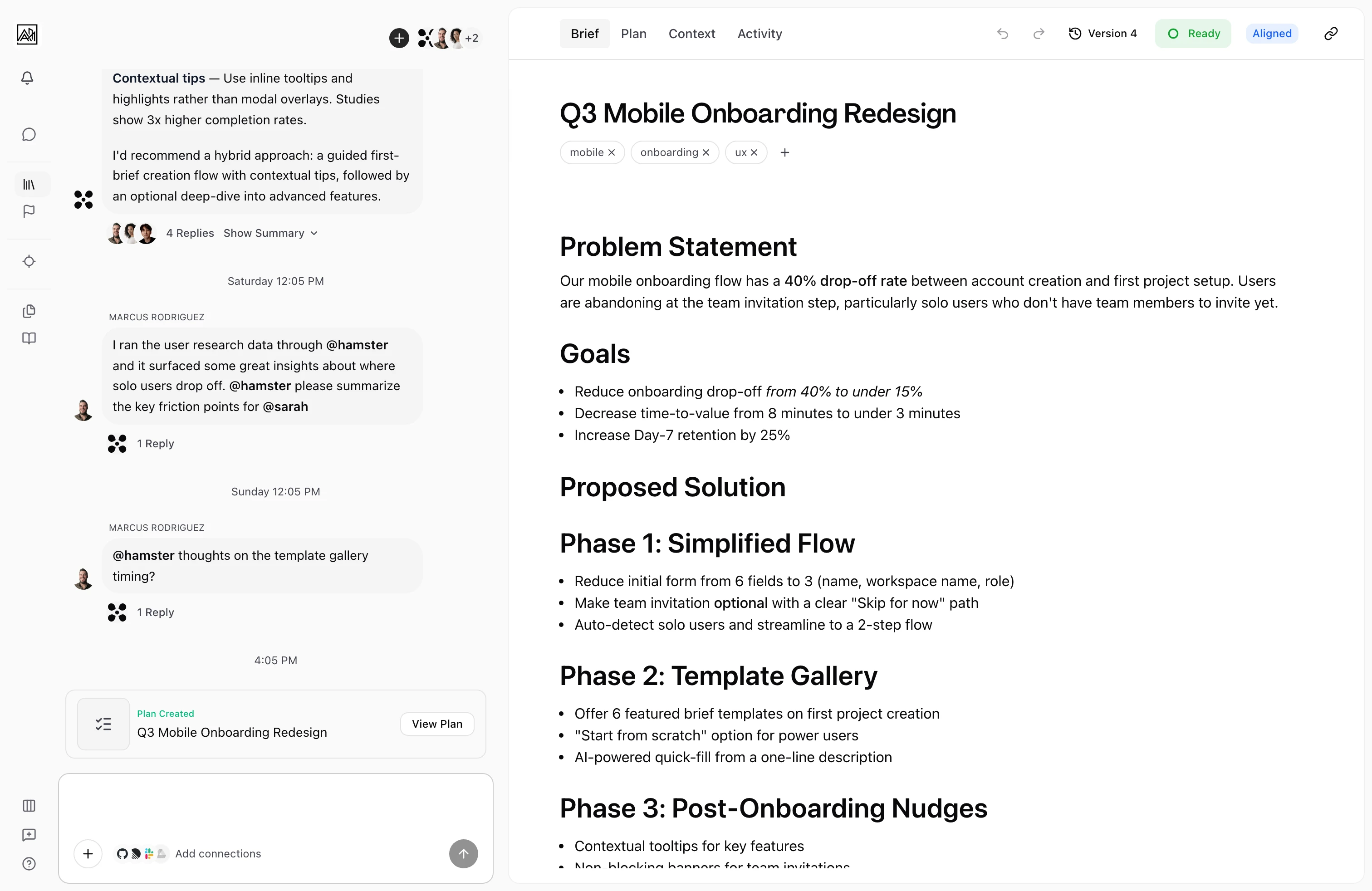

How It Works
-
You send a message — Your message appears in the thread immediately. The agent receives it along with recent conversation history and any relevant workspace context.
-
The agent reasons — Before responding, the agent works through the problem. A collapsible "Thinking" section appears in the thread as it reasons, so you can follow along in real time — you don't have to wait for the full response to start reading its logic. This section closes automatically once the final response begins.
-
Tools run if needed — Depending on what you asked, the agent may run tool calls — searching context, creating a Brief, filtering Briefs by tag, casting alignment, fetching from a connected app. Each runs as a compact status indicator showing whether it's in progress, complete, or waiting for review.
-
The response streams in — The reply appears token-by-token with a blinking cursor at the end of the current word. Markdown — headings, bullets, bold, code — is applied as the text arrives.
-
Long answers move to a child thread — If the response is detailed, the agent relocates it into a child thread automatically and posts a card in the parent so you can jump in. Plan generation and Brief drafting always run in their own child threads.
-
You review and continue — When streaming ends, the cursor disappears. If the agent edited a document, accept/reject buttons appear so you can review the diff before applying. Otherwise, you can reply directly.
Auto-Threading
Detailed answers, Brief drafts, and Plan generation move out of the main chat into child threads automatically. The parent thread keeps a card linking to the child so the conversation stays followable.
The rules:
- Long answers (multi-paragraph explanations, design or implementation Plans, migrations) move on their own.
- Brief and Blueprint creation always run in a dedicated child thread, with the Brief card landing back in the parent on the agent's first reply.
- Plan generation gets its own child thread when triggered from chat. The plan-generation card streams progress live and stays in sync if you navigate away and come back.
- Pending tool calls in a child thread show an amber dot on the card in the parent so you can spot work that needs attention.
- Solo threads (no other participants) don't get the share-summary banner — it only appears when other people are involved.
Reasoning Through Your Workspace
The agent doesn't rely on isolated keyword matches. It traverses the relationships between Briefs, Initiatives, Tasks, documents, and conversations to assemble higher-signal answers. It's also team-aware and time-aware — it can prioritise context based on who's involved and what changed recently, so responses stay grounded in your team's current reality.
Because it follows relationships rather than matching keywords, you can ask "why did we decide this" and the agent walks the Context Graph back to the Brief or message where the call was actually made.
Ask a vague, high-level question and the agent pulls the relevant context behind the scenes, answering with what's landed, what's in flight, and what needs attention.
Working with Files and URLs
- Drop a
.figfile — Figma files are accepted as a chat upload. The agent extracts the design context (pages, frames, text, components) and uses it as grounding for whatever you ask next. - Paste a Figma URL — public Figma files work without auth; private ones use the Figma OAuth connection. Either way, the agent renders the file as a thumbnail with structured content the agent can reference.
- Drop a PDF or markdown file — both are extracted and indexed for the agent.
- Paste any URL — most pages are scraped and summarised so the agent can use them as context.
Key Capabilities
- Streaming responses: Replies appear progressively. You can start reading before the agent has finished writing. Incomplete markdown renders gracefully while streaming.
- Auto-threading: Long answers, Brief drafts, and Plan generation move to child threads automatically with a clickable card in the parent.
- Live reasoning: A collapsible "Thinking" section streams the agent's reasoning in real time — visible in regular chat conversations as well as Brief, Blueprint, and Plan generation. You can follow the agent's logic as it works, not just after it's finished.
- Tool call indicators: Tool calls render in-thread as compact cards with status. Pending tool calls in a child thread surface as amber dots on the parent's branch entry.
- Document change review: When the agent edits a document, accept/reject buttons appear with a diff preview. Changes made while you were away show a "View pending changes" prompt before the buttons.
- Follow-up questions: When the agent needs more information, it can respond with a structured set of questions in the input area, stepping you through each one. These persist across page refreshes — your in-progress answers don't disappear if you reload.
- Mention
@hamsterdirectly: Address the AI in any thread by mentioning@hamster. Mixed mentions like@hamster do this, @bob what do you think?always trigger Hamster — Hamster never gets filtered out by other mentions in the same message. - Sticky context: After you mention
@hamster, follow-ups stay routed to Hamster without re-mentioning. After@bob, follow-ups stay with Bob until Hamster is explicitly re-mentioned. - Hamster has its own avatar: The AI shows up as a distinct participant in thread views, with its own avatar in headers, reply indicators, tool calls, and annotation messages — so it's always clear who said what.
- Plan generation from any chat: Trigger Plan generation from the main chat or a Brief chat. The plan-gen card lives in whichever thread you started it from, and reaches a terminal state even if you navigate away mid-flight.
- Stuck-chat recovery: If a service hiccup leaves a chat appearing to hang, the next message recovers the lock and the stale items are filtered out automatically. You don't get stuck on "Message is already being processed" anymore.
- Reviewer-safe: Teammates with the Reviewer role can ask questions and read replies, but write actions (creating Briefs, editing documents) are blocked at the agent level — not just hidden in the UI.
- Live voice (This feature may need to be enabled for your workspace.): Hold the microphone button in the chat input (or use the keyboard shortcut Cmd+Shift+S on Mac, Ctrl+Shift+S on Windows) to push-to-talk. The agent responds with text in the thread and synthesised audio.
Tips
- The "Thinking" section streams live in every conversation — you don't have to wait for the full response to start following the agent's reasoning. If you want to understand a specific decision, expand it and read the steps as they arrive.
- When the agent produces a document change, click "View Pending Changes" before accepting or rejecting to see a side-by-side diff.
- Drop the customer-call recording, the design file, and the linked context before asking for a brief. The agent uses everything attached to ground its work, so the Brief comes back in the right shape on the first try.
- If the agent keeps drifting on the last 30% of an answer, it's usually a context problem — paste in the strategy doc, the customer transcript, or whatever else is missing, and the next loop will converge.
Related
- Thread Messaging — The full message experience, including file attachments and URL previews
- Thread Branches — Working in focused sub-conversations
- Mentions and Notifications
- AI Features
- Skills and Methods